Webhook、IMAP
想像一家法律事務所,客戶經常透過 LINE 或 Email 詢問自己的案件進度。例如,張先生可能晚上透過 LINE 傳來訊息:「我想了解目前離婚訴訟案件的進展。」又或者王小姐寫了一封 Email 詢問:「上週提交的合約審查案件現在進度如何?」
對律所而言,這類查詢十分常見,但往往發生在非上班時間。傳統作法中,律所助理需要人工翻閱 系統中的案件紀錄,再一一回覆客戶,不僅耗時耗力,遇到深夜或週末來信也無法及時答覆,影響客服體驗。
上述場景突顯了痛點:客服人員花費大量時間在查詢與回覆重複性問題,而客戶期望即時獲得更新,甚至 24 小時不打烊的服務。那麼,有沒有辦法讓系統自動處理這些常見的案件進度詢問,讓律所能同時提升效率與服務品質呢?
本篇將聚焦這個需求,介紹如何運用 Odoo + 大型語言模型(LLM) 來打造智慧客服機器人:由 AI 即時解析來自 LINE、Email 的提問,自動查詢 Odoo 案件資料並生成專業回覆,減輕人工負擔,讓律所客戶服務升級。
要實現上述自動化客服,我們需要串起多個元件:通訊管道(LINE / Email)、中介服務(FastAPI)、ERP 系統(Odoo 18),以及AI 引擎(OpenAI GPT-5)。下圖展示了整體架構與訊息流程,從客戶發送訊息一路到 AI 回覆產生並返回客戶:
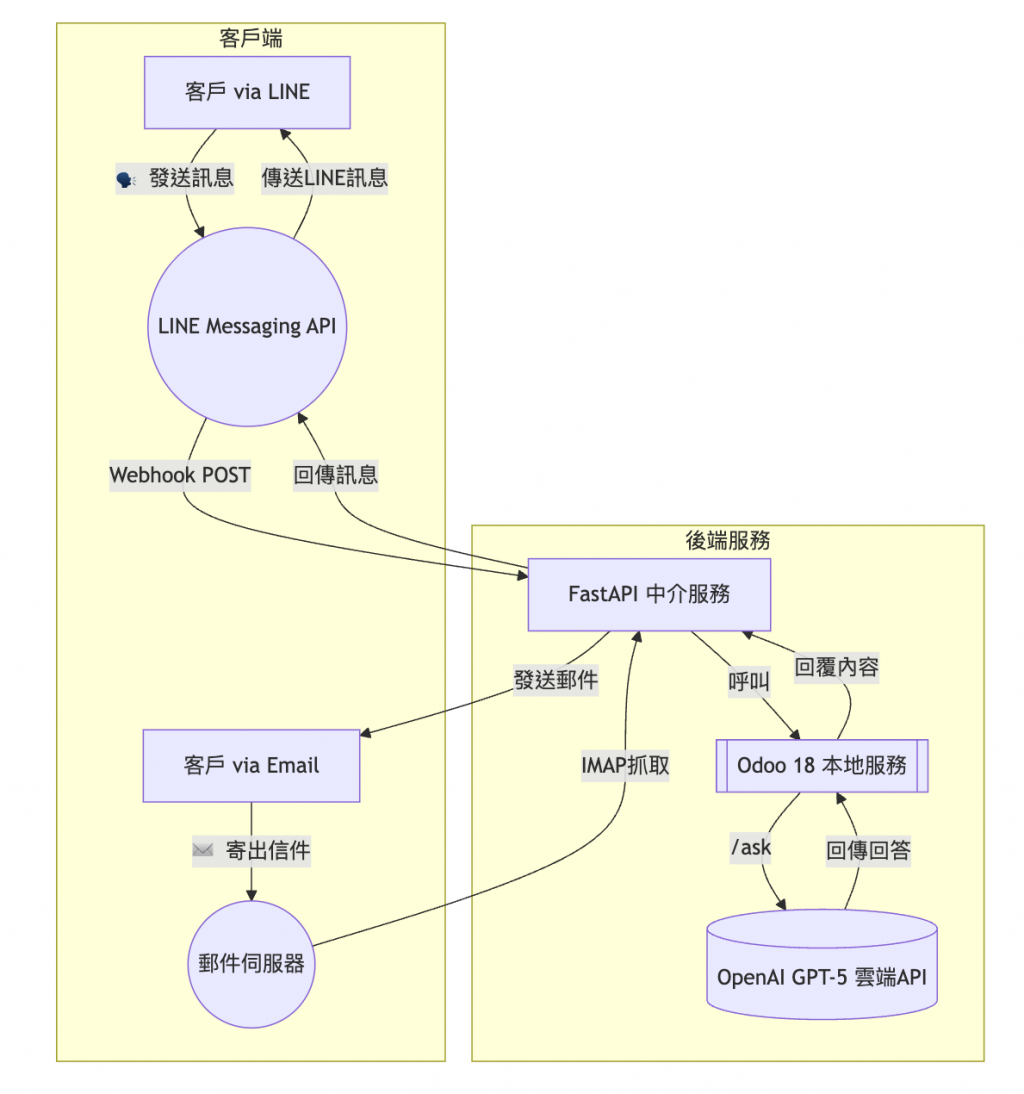
如上所示,LINE 和 Email 作為前端入口,將客戶的提問帶入我們的系統後端:
接著,在 FastAPI 中介服務中,我們會將這些外部訊息轉交給後端主要應用 Odoo。由於我們採用 Odoo 18 on-premise 環境,可以靈活地透過自訂 API 接口 或資料庫查詢,取得內部所需的案件資訊。
Odoo 在拿到客戶問題後,會觸發 GPT-5 啟動智慧應答流程:組裝詢問內容與案件背景形成 Prompt,呼叫 OpenAI GPT-5 模型獲得回答。隨後,Odoo 將 AI 回覆結果返回給 FastAPI。
最後,由 FastAPI 負責將回答分別傳回原來的通訊管道:
整體而言,這個架構讓 Odoo 扮演企業應用層,負責業務邏輯與資料存取,而 FastAPI 則充當與外部溝通的中介,串聯各種管道與 AI 雲服務。兩者透過 API 互動,界線清晰、模組化程度高,有利於後續維護與擴充。例如,未來若想增加更多 AI 功能(如自動翻譯、意圖分析等),我們只需在 FastAPI 增加新 route 或微服務,Odoo 呼叫對應接口即可,整體設計非常靈活。
首先,我們需要在 LINE 開發者平台為律所申請一個 Messaging API 頻道,取得 Channel Secret 和 Access Token。
接著在 Odoo 伺服器(或相關中介服務)公開一個 Webhook URL,並在 LINE 後台將此 URL 綁定為 webhook。
當客戶傳送 LINE 訊息給律所的官方帳號時,LINE 會將包含該訊息的事件資料(JSON 格式)POST 到我們的 webhook。透過 FastAPI,我們可以解析這份資料,取得用戶ID(以識別是哪位客戶)和訊息文字等資訊。因為 LINE 的 API 規範要求我們在短時間內對此 webhook 請求回應,所以 FastAPI 在接收後會馬上處理(如呼叫 Odoo 獲取回答,稍後詳述)並回傳狀態 200。
之後要將 AI 的回答發給用戶,需使用 LINE 提供的 Reply API:帶上從 webhook 事件中獲得的 replyToken 和欲回傳的文字內容,再以 HTTP POST 請求發送到 LINE 平台,即可將訊息推送給客戶。整個流程等同於模擬人工作答覆,只是由程式自動完成。
對於電子郵件,我們有兩種途徑:其一是利用 Odoo 的 mail gateway 功能,為客服信箱設定一個對應 Odoo 模組的收信地址(例如 helpdesk@lawfirm.com 對應 Odoo 客服工單)。
當客戶發信到該地址時,Odoo 會自動將郵件內容匯入對應的記錄模型中(如建立工單並附上郵件內容)。我們可以透過自訂自動動作,偵測到新郵件記錄後,觸發 AI 回覆流程。
其二則是在 FastAPI 中撰寫IMAP 收信邏輯,定期(例如每分鐘)連線郵件伺服器檢查新郵件:透過 Python 的 imaplib 或相關套件登入信箱、搜尋未讀郵件,解析取得寄件人地址及郵件內容。再將這些資訊傳遞給 Odoo 或 AI 服務處理,產生回覆後使用 smtplib 自動寄信回去給寄件人。
兩種方法中,利用 Odoo 內建郵件 route 更方便,因為許多步驟(如郵件解析、送信)已由框架處理。但無論哪種方式,核心是在取得郵件文字內容後,交給 AI 產生回應,並將回應郵件發送出去。接下來,我們會說明 Odoo 如何將 LINE 或 Email 的提問結合 GPT-5 進行回答。
當外部訊息經由 FastAPI 進入 Odoo 後,就進入了內部處理階段。我們可以在 Odoo 中設計一個 「客服機器人」模組 或直接擴充現有的 客服/案件模型 來處理這件事。以下是系統設計的幾個重點步驟:
身份與上下文識別:透過 LINE 傳來的 userId 或 Email 的寄件人地址,我們可以在 Odoo 的資料庫中找到對應的客戶(例如比對 Odoo 內的聯絡人名錄)。進一步地,若我們針對每個案件都有紀錄客戶資訊,便能據此鎖定該客戶相關的案件記錄。例如,在 Odoo 的 工單 (Helpdesk) 或 專案專案 模組中,每個案件都關聯到一個客戶,因此我們可搜尋客戶目前開放的案件以取得狀態。若客戶提問中包含了案件編號等額外線索,也能用來精確匹配特定案件。這一步確保 AI 在回答時能掌握正確的背景,而不會張冠李戴。
組裝 AI 提問(Prompt):有了客戶的問題內容和相關案件資訊,我們便構造一個發送給 GPT-5 的 Prompt。Prompt 中我們會融合客戶詢問和案件背景,讓 AI 理解問題的來龍去脈。例如,我們可以組成這樣的文字:
「客戶詢問:『XXX?』。此客戶相關案件摘要:YYYY。請以專業律師助理口吻回答客戶的問題,語氣禮貌且簡潔明確。」
如此一來,GPT-5 在生成回答時既有提問,也有必要的背景知識支援,降低答非所問或捏造資訊的機率。同時在 Prompt 裡我們也能要求回答風格,例如強調專業、使用禮貌稱謂等,以符合律所形象。
呼叫 LLM 模型:接下來,Odoo 通過先前建置的 FastAPI /ask 接口或直接使用 OpenAI SDK,將這個 Prompt 發送給 GPT-5 模型,並等待生成回答。由於 GPT-5 屬於運算量大的雲端模型,我們通常會設定一個合理的逾時時間(例如 30 秒)以避免久無回應卡住系統。在 Odoo 與 FastAPI 的串接實現上,我們可以採用標準的 HTTP POST 請求,這部分可以參考 Day 7:環境建置:連接 OpenAI GPT5 與 Odoo 。
取得並格式化回答:當 GPT-5 返回建議的回答文本後,Odoo 收到的是一段純文字。我們可以在此對內容稍加處理,確保格式與語氣符合需求。例如,我們可以預先定義一些回答模板或片語,使 AI 回覆中包含稱謂(如「親愛的張先生您好:」)以及客戶滿意度關懷用語。此外,如果 GPT 回覆中遺漏了我們希望包含的關鍵資訊(例如案件號或下一步日期),也可以在回傳前加上相關說明。總之,這一步的目的是讓最終發給客戶的內容完整且專業。
回傳回覆給客戶:最後,經處理的回覆會透過前述管道送回客戶端:Odoo 可以直接調用 LINE Messaging API 傳訊息,或使用 Odoo 的 mail.mail 功能發送 Email 給客戶。以 LINE 為例,只要將客戶的用戶ID(或 replyToken)和要傳送的文字打包成 JSON,POST 到 LINE 的推送/回覆消息接口,即可由 LINE 平台將訊息下發給用戶。Email 則可透過 Odoo 的郵件隊列自動發信或直接使用 SMTP 寄送。此外,為了方便日後查詢與分析,我們也可以將每次問答結果記錄在 Odoo 中(例如寫入對應案件的聊天紀錄模型或註解),形成一個客服對話歷程。這樣管理員日後可以查看 AI 曾經如何回答客戶,必要時介入校正 AI 的資訊或語氣。
經過上述流程,律所的 LINE 和客服信箱已經由一位 24/7 的 AI 助理在值守。不論客戶何時發問,系統都能自動給出即時又專業的答覆。接下來,我們透過部分關鍵程式碼,進一步了解實作細節。
下面我們提供部分模組與服務的程式碼範例,展示如何串接各元件。範例將涵蓋:FastAPI Webhook 如何接收 LINE 訊息並調用 Odoo,以及 Odoo 自訂函式如何構造 Prompt、呼叫 GPT-5 並返回答案。
首先是 FastAPI 的 webhook 實作範例。它負責接收 LINE 的 HTTP POST 請求,解析其中的訊息,然後將客戶提問轉交給 Odoo 獲得回答,最後透過 LINE API 回覆客戶:
from fastapi import FastAPI, Request
import requests
app = FastAPI()
LINE_CHANNEL_TOKEN = "<你的 LINE Channel Access Token>"
@app.post("/line_webhook")
async def line_webhook(request: Request):
data = await request.json()
event = data["events"][0] # 假設每次只接收一個事件
user_id = event["source"]["userId"] # 客戶 LINE 用戶ID
user_message = event["message"].get("text", "")
# 呼叫 Odoo API,將用戶ID與訊息傳送以獲取 AI 回覆
odoo_api_url = "http://odoo-server:8069/api/get_answer" # 假設已實作 Odoo API
payload = {"user_id": user_id, "message": user_message}
resp = requests.post(odoo_api_url, json=payload)
answer_text = resp.json().get("answer", "(查無回覆)")
# 使用 LINE Reply API 將答案發送給用戶
reply_token = event["replyToken"]
line_api_url = "https://api.line.me/v2/bot/message/reply"
headers = {
"Authorization": f"Bearer {LINE_CHANNEL_TOKEN}",
"Content-Type": "application/json"
}
reply_body = {
"replyToken": reply_token,
"messages": [ {"type": "text", "text": answer_text} ]
}
requests.post(line_api_url, headers=headers, json=reply_body)
return {"status": "ok"}
上述程式碼中,FastAPI 定義了一個 /line_webhook route,專門處理 LINE 傳來的事件。收到請求後,我們:
userId(用於識別用戶)和 message.text(用戶發送的文字)。requests.post 呼叫 Odoo 提供的一個 API(這裡假設我們在 Odoo 實作了 /api/get_answer 接口)。我們傳去 user_id 和 message,讓 Odoo 幫我們產生回答。answer 文字。如果沒有拿到答案,則用預設訊息(如「查無回覆」)避免空白。replyToken 和準備好的回答文字一同POST回 LINE 平台。如此 LINE 即會將我們的回答發送給對應的用戶。最後回傳一個簡單的狀態訊息表示 webhook 完成。💡 Gary’s Pro Tip|處理 LLM 回答逾時
實務上,呼叫 OpenAI 等 LLM 服務可能遇到回應延遲甚至超時。在上述流程中,我們是在 webhook 裏同步等待 Odoo 給答案,再立即回覆給 LINE。若 AI 耗時過久(超過 LINE webhook 的時間限制),可能導致回覆失敗。解法之一是:先迅速回應 LINE 一條預設訊息(例如:「我們正在查詢您的案件,稍後將答覆您。」),再由 AI 計算完成後主動推送答案給用戶。這可透過 LINE Push API 實現。另一個策略是在
requests.post調用 Odoo 或 OpenAI 時設定timeout參數並妥善錯誤處理。一旦發生超時或失敗,就走備援路徑:例如回覆客戶「系統繁忙稍後回覆」,同時通知人工接手。總之,要為 AI 服務的不確定性預留應變機制,以保障使用者體驗。
接下來看看 Odoo 端的實作。我們可以創建一個自訂模型或控制器來處理外部傳入的詢問。以下範例展示在模型方法中如何取得案件資料並串接 GPT-5:
import requests
from odoo import models
class Case(models.Model):
_name = "legal.case"
# ... 定義案件的相關欄位,例如 number、partner_id、status 等
def get_ai_answer(self, inquiry_text, partner_id):
# 查找對應客戶的案件記錄(假設每位客戶僅有一件進行中案件)
case = self.search([('partner_id', '=', partner_id), ('status', '!=', '已結案')], limit=1)
if case:
case_info = f"案件編號{case.number},狀態:{case.status}。"
else:
case_info = "(無法找到相關案件資訊。)"
# 組合 Prompt 將客戶問題與案件資訊提供給 AI
prompt = (
f"客戶詢問:「{inquiry_text}」\n"
f"{case_info}\n"
f"請以專業禮貌的口吻回答客戶的問題,"
f"如果缺少必要資訊,請回答「很抱歉,相關資料不完整」。"
)
try:
resp = requests.post("http://localhost:8000/ask", json={"prompt": prompt}, timeout=30)
answer_text = resp.json().get("answer", "")
except Exception as e:
answer_text = ""
# 將回答結果返回,供外部調用時使用
return answer_text
以上程式碼定義了一個 legal.case 模型的 get_ai_answer 方法:
partner_id 搜尋當事人相關的案件(例如篩選進行中的案件)。若找到就組裝案件資訊文字(如 案件編號與狀態),找不到則給一段括號訊息表示無資料。requests.post 呼叫本地執行的 FastAPI /ask 接口,把 prompt 丟給 GPT-5。並設定 timeout=30 秒防止阻塞過久。一旦拿到回傳結果,取出其中的 answer 純文字。若呼叫過程發生錯誤或逾時,這裡簡單地將 answer_text 設為空字串(實務上可更細緻處理)。answer_text。這個方法可以被 Odoo 控制器或其它業務邏輯呼叫。例如我們可以在 Odoo 建立一個 /api/get_answer 的 Controller,當 FastAPI 將 user_id 和 message 傳進來時,先找到對應 partner,再呼叫此 get_ai_answer,最後將結果用 jsonify 回傳。如此即可完成 FastAPI -> Odoo -> GPT-5 -> Odoo -> FastAPI 的串接流程。在這段 Odoo 程式中,我們看到 Prompt 包含了實際案件狀況,並直接告知模型在資訊不足時應如何應對。這種設計能大幅降低 AI 的幻覺風險,因為模型不需要自己猜測案件進度,只需根據我們提供的資訊回答即可。
💡 Gary’s Pro Tip|避免 AI 幻覺,提升回答可靠度
幻覺(hallucination) 是大型語言模型亂湊答案的常見問題。為了避免這種情況,在 Prompt 設計上可以採取幾項措施:首先,明確限制模型僅能利用提供的資訊,並反覆強調不得編造。例如在指令中加入「僅根據以上資料回答」等語句。其次,設置模型的回覆策略,要求它在資訊不足時直接坦承(如回答「資料不足,無法確定」),而不是硬掰。您也可以調低生成時的 temperature 讓回答更保守。透過這些 prompt 工程技巧,可有效提高 AI 回覆的可靠性與準確性。
💡 Gary’s Pro Tip|客製回覆語氣與風格
不同產業的客服用語風格各異:法律業強調專業嚴謹,電商客服則追求親切熱情。要實現客製化回覆語氣,可以在 Prompt 裏明確描述所需的風格,例如:「以專業律師助理口吻回答」或「以貼心友善的語氣回答顧客」等。甚至可以提供範例語句讓模型模仿。此外,OpenAI 模型的 system prompt 也能設置整體語氣基調。透過反覆微調這些提示詞,您可以讓 AI 調整用詞和句型,以符合品牌形象。一旦找到理想的語氣模板,可以將其固定在程式中,確保每次回覆都保持一致的風格與品質。
引入 Odoo 結合 LLM 的自動化客服後,我們最關心的莫過於實際效率提升如何。以下以兩項關鍵指標說明:
綜合上述,透過量化數據可以明確看到這套 Odoo + LLM 智慧客服方案為律所帶來的效益:即時的回覆縮短等待、機器人處理大部分查詢、人工專注於高價值任務。在下一節,我們將更全面地討論其商業價值。
導入 Odoo 整合 GPT-5 的客服自動化方案,為法律事務所帶來了多方面的商業價值:
今天我們探討並實作了如何運用 Odoo 18 搭配 OpenAI GPT-5 來打造法律事務所的智慧客服系統。從 LINE、Email 多管道接入客戶詢問,到 Odoo 串聯 LLM 自動生成專業回覆,再到最終將答案發送給客戶,全流程實現了高度自動化。透過適當的系統架構和 Prompt 設計,我們確保 AI 回覆既快速又準確,幫助律所大幅提升了客服效率,強化了其專業服務形象。
整合 LLM 到企業應用中的價值在此案例中展露無遺:它不僅節省了時間與成本,更帶來服務水準的飛躍。在法律科技化的道路上,客服自動化只是其中一塊拼圖!


